Project Overview
The Challenge of AI-Generated Misinformation
In 2025, as artificial intelligence continues to evolve, my MSc Cybersecurity Individual Project addresses a pressing issue: the detection of fake Cyber Threat Intelligence (CTI) generated by advanced models like Chat GPT-4. Cyber Threat Intelligence is essential for security professionals to understand and mitigate threats, but AI-generated fake intelligence can lead to misplaced defensive efforts and wasted resources.
My project develops a detection system using Logistic Regression and CountVectorizer text processing to differentiate authentic CTI from AI-generated fakes. I've collected hundreds of real CTI reports from MITRE ATT&CK and generated 200 fake samples using Chat GPT-4, creating a robust dataset to train my model. The system not only classifies reports but also provides confidence scores through a Flask-based web interface, making it practical for real-world use.
This work is critical because fake CTI, if undetected, could mislead cybersecurity defences, confuse Open-Source Intelligence (OSINT) communities, and provide adversaries with opportunities to exploit vulnerabilities. My research builds on prior studies while pushing the boundaries with Chat GPT-4's advanced capabilities, aiming to safeguard the integrity of cybersecurity intelligence in an AI-driven future.
Background and Motivation
The motivation for this project stems from the increasing sophistication of AI and its potential to disrupt cybersecurity. Having read dozens of articles on fake CTI and misinformation detection, I've observed a growing concern: AI models like Chat GPT-4 can generate reports that mimic the tone, structure, and terminology of legitimate CTI, making them difficult to spot without advanced tools.
Real CTI—from sources like MITRE ATT&CK—contains precise details such as CVE numbers, software versions, and credible references, while fake CTI often relies on vague or technically implausible claims. This gap inspired me to create a system that leverages machine learning to protect organisations from AI-driven deception.
The stakes are high: a single fake report could misdirect resources, delay responses, or even enable attacks. My project aligns with the UK's National Cyber Security Centre (NCSC) CyBOK framework, particularly in network security and threat intelligence, and addresses a real-world challenge that's escalating in 2025 as AI technology advances. I'm driven by a passion to ensure cybersecurity professionals can trust the intelligence they rely on.
Methodology
A Systematic Approach to Fake CTI Detection
My approach to detecting fake CTI is systematic and multi-faceted, combining data collection, text processing, model training, and a user-friendly interface. Here's a detailed breakdown:
Data Collection:
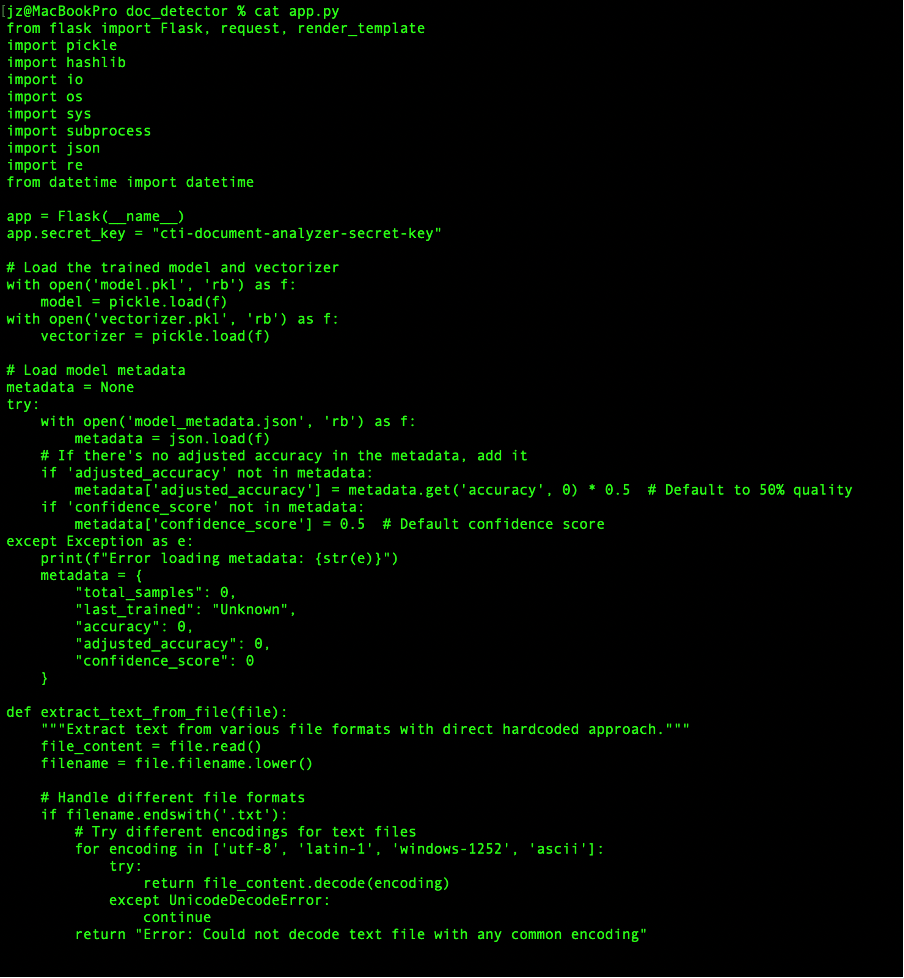
I began by gathering authentic CTI reports from MITRE ATT&CK (mitre.org), a gold standard in the field. Using Python, I wrote a custom web-scraping script to extract hundreds of reports—far too many to collect manually. Each file was saved with "real" in its filename (e.g., "real_mitre_report_001.txt") and stored in a dedicated training folder. Next, I prompted Chat GPT-4 to study MITRE's report structure—headings, technical jargon, and formatting—and generate 200 fake CTI samples. These fakes were designed to closely resemble real reports, saved with "fake" in their filenames (e.g., "fake_cti_001.txt"), and placed alongside the real data. I plan to expand this dataset by scraping additional CTI from other reputable sources to enhance the model's ability to generalise across different styles and formats.
Data Preparation:
To structure the data for training, I wrote Python code that scans filenames, automatically labelling reports as "1" (real) or "0" (fake) based on the "real" or "fake" keywords. This labelled data was compiled into a CSV file with columns for file paths, text content, and labels, providing a clean dataset for machine learning.

Text Processing:
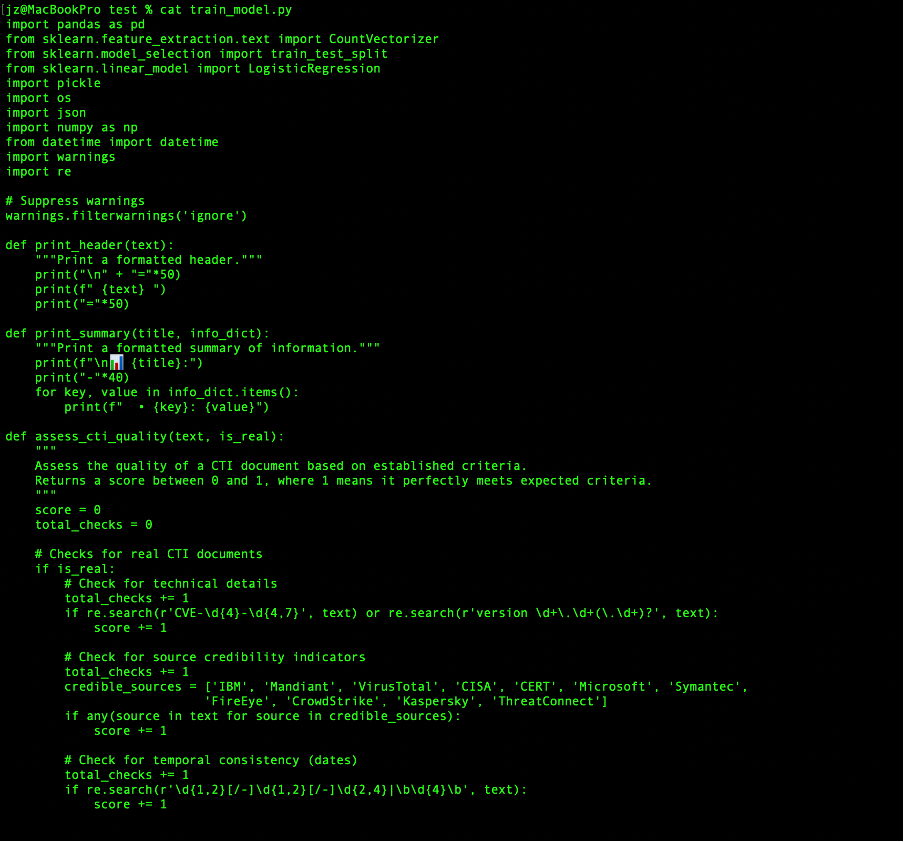
I used CountVectorizer to convert raw text into numerical features by counting word occurrences across all documents. For example, in a real CTI report stating "malware infected server via CVE-2023-1234," words like "malware," "infected," "server," and "CVE-2023-1234" become features with associated counts. I limited the analysis to the 300 most common words to focus on distinguishing patterns, such as technical terms in real reports versus vague phrases in fakes.
Model Training:
The core of my system is a Logistic Regression model, which calculates the probability that a document is real or fake based on word frequencies. For instance, a report with frequent mentions of "CVE-2023-1234" and "patch" might score a 90% probability of being real, while one with "sophisticated attack" and no specifics might score 20%, indicating a fake. I split the dataset into 80% training and 20% testing sets to ensure robust evaluation, training the model to recognise patterns from both MITRE's real data and Chat GPT-4's fakes.
Detection System:
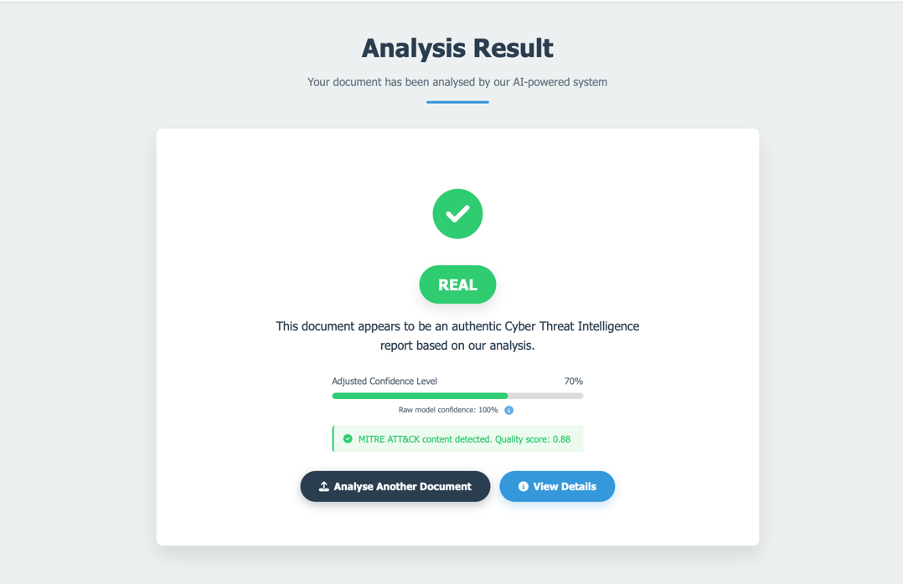
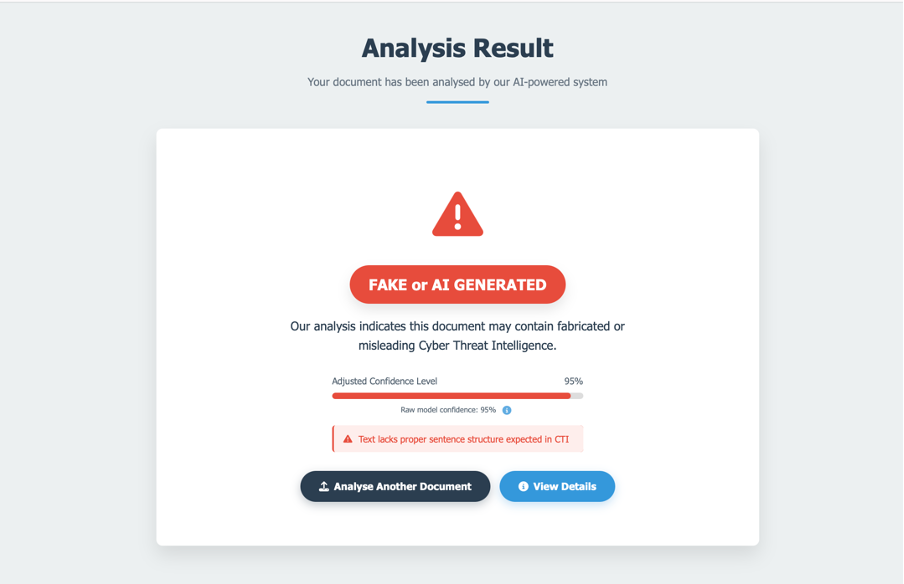
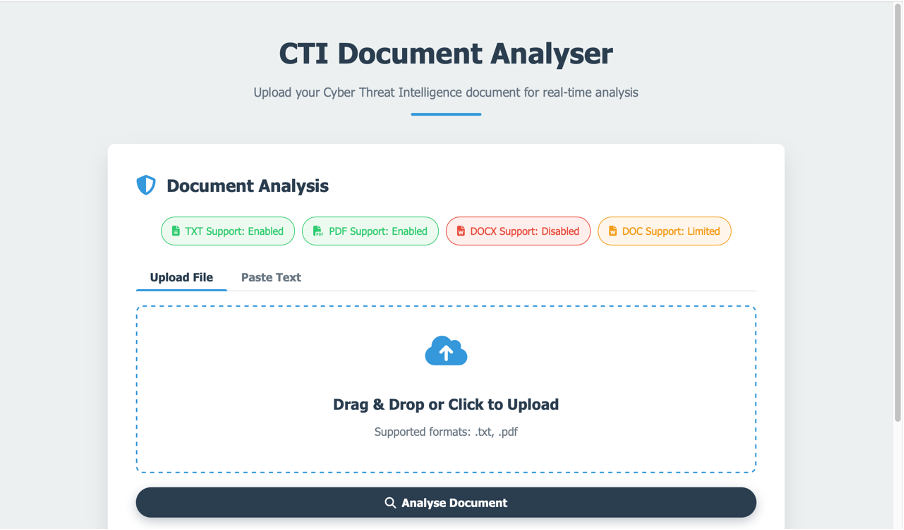
I developed a web interface using Flask, a Python framework, allowing users to upload files (TXT, PDF) or paste text directly. The system extracts text, validates it for basic CTI characteristics (e.g., length, presence of technical terms), and applies the trained model. Results are displayed with confidence scores—e.g., "75% likelihood of being real"—making it accessible and actionable.
Evaluation:
The model's performance is measured by accuracy, comparing predicted labels against the test set's true labels. I've also identified key indicators: real CTI features specifics like "CVE-2021-34484" or "Windows 10 version 21H1," while fakes often include impossibilities like "Linux kernel in Windows" or vague boasts like "perfectly executed attack."
Current Progress
Project Status as of Mid-2025
As of mid-2025, my project is well underway. Since January, I've collected over 200 real CTI reports from MITRE ATT&CK using my Python scraper, ensuring a diverse sample of attack techniques and vulnerabilities. I've also generated 200 fake reports with Chat GPT-4, carefully prompting it to replicate MITRE's style while subtly introducing flaws.
The dataset is fully labelled and organised in a CSV, with my Logistic Regression model trained and achieving promising initial accuracy (specific figures pending further testing). The Flask web interface is functional: users can upload a CTI document, and within seconds, the system processes it and returns a classification with a confidence score.
I've identified distinct patterns—real reports are grounded in specifics, while fakes lean on ambiguity—which the model effectively detects. My next steps include collecting more CTI from additional sources and refining the model to boost accuracy.
Expected Outcomes
By August 2025, I aim to deliver a comprehensive package:
- A fully trained detection model with documented accuracy, capable of distinguishing real CTI from Chat GPT-4 fakes with high reliability.
- A detailed analysis of Chat GPT-4's deception capabilities, highlighting how its language generation has evolved since earlier models.
- A comparison with prior studies (e.g., 2021 research on Chat GPT-2), showing the increased threat posed by modern AI.
- Practical guidelines for cybersecurity teams, such as red flags to watch for in CTI (e.g., lack of CVE numbers) and how to integrate my system into their workflows.
- An expanded dataset incorporating CTI from multiple sources, making the model more adaptable to varied report styles.
This work will provide both academic insights and a tangible tool for the cybersecurity community.
Skills and Technologies
Machine Learning
Implemented Logistic Regression for classification, fine-tuning it for text-based threat detection
Natural Language Processing
Mastered CountVectorizer to extract meaningful features from unstructured CTI text
Programming
Python scripts for web scraping, data organisation, model training, and Flask development
Web Development
Built a Flask-based interface, handling file uploads, text processing, and result visualisation
Cybersecurity Knowledge
Deep expertise in CTI, threat intelligence analysis, and AI-driven misinformation
Data Management
Structured large datasets into CSV formats, ensuring clean, labelled inputs for training
Key Insights and Future Work
Through hands-on work and article research, I've uncovered critical lessons:
Real CTI Characteristics:
Specifics rule—CVE numbers (e.g., CVE-2021-34484), software versions (e.g., Windows 10 21H1), credible sources (e.g., CISA), precise dates, and technical mechanisms (e.g., buffer overflow) anchor authenticity.
Fake CTI Red Flags:
Vagueness reigns—phrases like "sophisticated attack" or "undetected for years" without evidence, technical impossibilities (e.g., "Linux kernel in Windows"), and misused jargon signal deception.
Model Effectiveness:
Even a straightforward approach like Logistic Regression, paired with CountVectorizer, can achieve strong results when trained on well-curated data, proving simplicity can be powerful.
AI's Evolution:
Chat GPT-4's fakes are scarily convincing compared to earlier models, highlighting the urgency of detection tools.
Future Directions
Looking ahead, I plan to explore advanced techniques like deep learning (e.g., BERT models) to capture nuanced linguistic patterns, expand the system to detect fake CTI in other domains (e.g., phishing emails), and collaborate with industry partners to test it in real-world scenarios. My extensive reading has convinced me that this is just the beginning—AI's threat potential will keep evolving, and I'm eager to stay ahead of the curve.
Results & Impact
Enhanced CTI Reliability
Cybersecurity teams will be able to verify the authenticity of threat intelligence before acting on it, preventing misdirection.
Advanced Detection Methods
Developed novel approaches to distinguish genuine technical content from AI-generated imitations using textual patterns.
Practical Implementation
Created an accessible tool with a web interface that security professionals can integrate into existing workflows.
Research Contribution
Advancing the field's understanding of AI-generated misinformation in technical domains like cybersecurity.